Déployer un firewall en VM sous Xen pour ma soeur II, le retour
Par Vanhu le lundi, avril 2 2018, 22:16 - Vieux con de hacker old school..... - Lien permanent
Il y a une éternité très très longtemps, dans une galaxie très lointaine quelques temps, nous avions vu comment déployer un firewall en VM sous XEN. Aujourd'hui, nous allons faire la même chose, mais en mieux.......
Y'a quelqu'un ?
Si vous êtes particulièrement attentifs, vous aurez peut être remarqué que le dernier billet sur ce blog datait d'il y a environ 4 ans (on ne va pas pinailler pour quelques semaines). Et maintenant que je viens de le dire clairement, même si vous avez le niveau d'attention d'un chaton, il faudra au moins quelques bonnes secondes et une baballe qui passe pour vous faire oublier ce fait..... Vous me croyez si vous voulez, mais il semblerait que des gens (je veux dire, de vrais gens, pas seulement des bots) viennent encore sur ce blog de temps en temps. Ne me demandez pas pourquoi, je n'en ai aucune idée, mais les logs sont formels !
Et comme ces billets techniques me servent avant tout de notes pour le jour où je devrai moi même tout refaire en urgence, ca ne change de toutes façons pas grand chose à ma décision de dépoussiérer un peu et faire de nouveaux billets..... et oui, je viens de parler de nouveaux billets au pluriel.......
Ah, et maintenant que je vais cliquer sur "publier", je me dis que, si je l'avais finalisé un poil plus vite, ça aurait pu être une bonne blague !
Disclaimer
Ma soeur a beau avoir fait quelques progrès avec son mac (et je parle bien ici d'un ordinateur), ce billet contient quand même plein de morceaux de trucs techniques plus ou moins dégoulinants qui traînent un peu partout (mais a priori, ni OGMs ni aucune trace de noix). En particulier, il est très nettement préférable d'avoir déjà fait un plan à trois avec une Debian et un Xen au moins une fois dans sa vie.....
Si vous êtes expert pour dézinguer tous les aliens au pied de biche sur Xen, c'est très bien, mais ca ne vous sera d'aucune utilité ici.
Comme toujours sur ce blog, les actions décrites ci après ont été réalisées par un Vieux Con de Hacker Old School (tm) professionnel, dans des conditions de sécurité optimales, et avec un safeword pour rebasculer sur l'ancien hyperviseur+firewall en cas de problème.
Et aucun animal mignon n'a été blessé, tué ou mangé pendant l'intervention.
Et donc, le même truc en mieux, c'est quoi ?
Oui, c'est bon, j'y arrive, on dirait que certains n'ont pas appris la patience avec le temps !!!
L'idée de base reste la même: une machine physique, une Debian qui fait tourner un hyperviseur Xen (d'où les prérequis......), et parmi les VMs, un firewall (dans mon cas, toujours un Stormshield SNS, bien évidemment, mais je suppose que le principe fonctionnera aussi avec des distribs spécialisées comme pfSense ou une autre distrib firewall|) qui doit pouvoir gérer des interfaces physiques comme s'il était un firewall physique avec ces interfaces, ainsi que d'autres interfaces purement virtuelles pour les autres VMs. Un truc dans cette idée là:
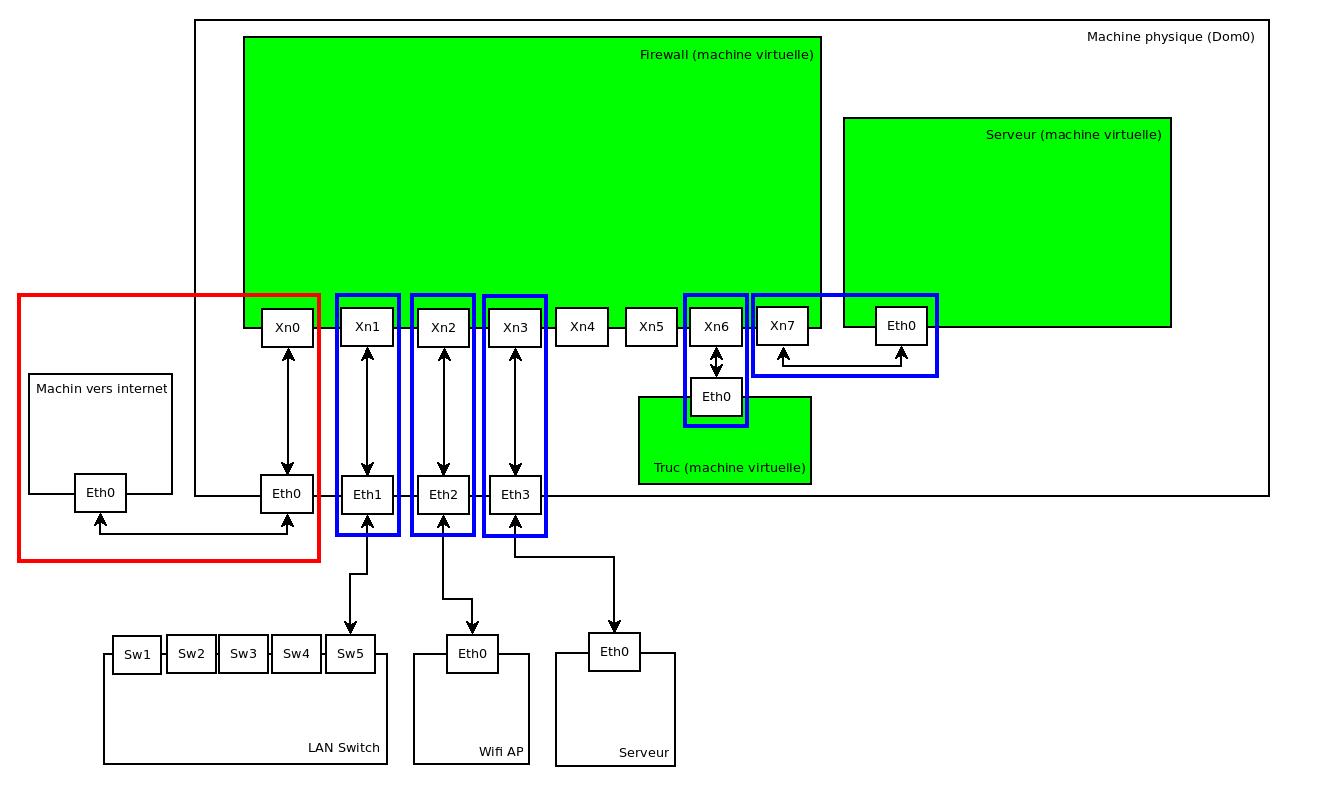 (oui, c'est exactement le même schéma que pour le billet précédent, maintenant que vous l'avez remarqué, vous savez où vous pouvez aller lire les explications un peu plus détaillées..........)
(oui, c'est exactement le même schéma que pour le billet précédent, maintenant que vous l'avez remarqué, vous savez où vous pouvez aller lire les explications un peu plus détaillées..........)
Mais en mieux..............
Premier point, tout utilise des versions plus récentes ! En 4-5 ans, vous imaginez ??? Rien que chez Debian, par exemple, bah il y a ....... 2 versions d'écart...... ok, c'est pas forcément le meilleur exemple.......
La version de Xen, par contre, fait un assez grand saut, puisqu'on était à l'époque en 4.1, et que nous allons cette fois-ci utiliser la 4.9 embarquée dans Stretch. Et là on commence à avoir des différences sérieuses: nous allons enfin utiliser le toolstack xl de Xen, et profiter de toutes les améliorations de performances et de support de fonctionnalités qui ont été faites pendant tout ce temps.
Ensuite, j'ai une nouvelle machine physique pour l'hyperviseur. Entre autres, la façade réseau de l'ancienne ressemble à ça:

alors que la façade de la nouvelle ressemble à ça:

Ne vous méprenez pas, ce n'est ici pas la taille qui compte (les 2 photos ne sont pas à la même échelle, déjà....), mais bien le nombre de trous d'interfaces réseau physiques, à savoir 24 sur le nouvel hyperviseur...... et on va vouloir s'en servir (éventuellement avec un peu de mauvaise foi si nécessaire, comme le nombre de RJ 45 réellement branchés sur la photo le laisse deviner......):
- Le bloc de 8 interfaces à droite sera considéré comme un simple switch pour le firewall.
- Les 4 interfaces avec des RJ45 bleus du milieu seront configurées en LACP. Note pour ma soeur: il n'est pas nécessaire d'avoir des RJ45 bleus pour faire du LACP, mais on s'y retrouve un peu plus facilement si on utilise des câbles de couleur différente......
- Ce LACP sera en bridge avec les 4 interfaces au dessus, pour avoir au final un gros switch dont la moitié en LACP.
- Les interfaces du bloc de gauche vont être groupées par paires (celle du dessus, et celle du dessous).
(j'expliquerai l'intérêt de chaque configuration au moment de la mettre en œuvre).
Jusqu'à récemment, je n'arrivais pas à démarrer une VM avec plus de 8 interfaces ethernet déclarées au total, et ma VM de firewall n'en gérait pas plus de 10. J'étais donc obligé de gérer toutes ces configurations directement sur l'hyperviseur.
Aujourd'hui, ces 2 limitations semblent avoir disparues, ou au moins avoir été repoussées: j'ai désormais une configuration fonctionnelle avec 20 interfaces pour la VM du firewall.
Cependant, il me parait plus pertinent de gérer les topologies réseau au plus près des connecteurs, tant d'un point de vue performances que pour la simplicité de la configuration: coté hyperviseur, on gère le câblage, et coté firewall on s'occupe du découpage logique du réseau, de la sécurité, etc.... Mais libre à vous de prendre uniquement la version simple de la configuration que nous allons voir, de relier chaque interface au firewall et de gérer les topologies complexes directement sur le firewall.
Autres solutions possibles
Eh oui, ce point n'a pas changé en 4 ans, il y a toujours d'autres solutions possibles ! Au delà du fait que, si j'avais choisi d'autres solutions, je me serais quand même retrouvé à écrire ce paragraphe, passons en revue les alternatives qui méritent un peu plus de détails
Xen ?
Pour mon firewall, je ne pouvais pas partir sur les technos de containers logiciels genre LXC ou Docker, il me fallait un vrai hyperviseur. Du coup, Xen fonctionne bien, je connais et j'ai l'habitude, il est officiellement supporté par les VMs SNS, et je n'ai toujours pas trouvé d'autre hyperviseur qui justifie le changement depuis le temps. Pour être tout à fait exact, je n'ai pas plus que ça cherché non plus.......
PCI Passthrough
On pourrait toujours passer les interfaces réseau directement à la VM du firewall, la techno semble plus mature qu'à l'époque. Cela ne permet pas de brancher entre elles des VMs. Dans mon cas, le firewall n'embarque pas les pilotes nécessaires, donc la solution ne fonctionnerait pas. Et le fait de séparer le câblage de la configuration réseau pure me permet d'avoir une vue plus simple coté firewall.
MACVLAN / MACVTAP
Je n'ai vu ces technologies que très rapidement, elles semblent être des alternatives potentielles pour le cas des interfaces physiques. Pour le peu que j'en ai vu, ce type d'interfaces n'est pas adapté pour raccorder d'autres VMs à la VM du firewall (si tu as des informations pertinentes qui contredisent cette affirmation, ça m'intéresse !).
OpenVSwitch
Cette fois ci, j'ai vraiment essayé OpenVSwitch.... une version intermédiaire de ce billet expliquait même que j'utilisais au final cette solution en production.... et puis je me suis retrouvé à essayer d'avoir des bridges openvswitch fonctionnels et configurés assez tôt au démarrage de mon hyperviseur pour pouvoir démarrer la VM firewall automatiquement...... et je suis revenu aux bridges classiques.....
Du coup, j'ai assez avancé dans mes tests, et il n'y a finalement pas beaucoup de différences au niveau de la configuration:
- il faut installer le paquet openvswitch-switch au lieu d'installer bridge-utils......
- il faut modifier /etc/xen/xl.conf pour lui dire d'utiliser le script vif-openvswitch par défaut (ou forcer ce script pour chaque interface de chaque VM, si vous aimez vous compliquer les fichiers de configuration pour pas grand chose......)
- la configuration des interfaces est un peu différente...... je vous aurais bien résumé comment on configure un bridge avec openvswitch, mais je viens un peu de vous dire que je n'ai pas réussi à avoir une configuration vraiment fonctionnelle en prod........
- on a les mêmes problématiques d'isolation des interfaces
- apparemment, on ne peut pas faire de tcpdump directement sur l'interface du bridge (mais j'ai repéré ce point peu de temps avant de rebasculer sur les bridges, donc l'info n'est peut être pas fiable......).
Installation de base
Dans le billet précédent, je n'avais pas du tout détaillé l'installation de base de l'hyperviseur, ni le fait de déployer une VM classique. Cette fois ci, il y a assez de subtilités techniques dans mon cas pour non seulement expliquer certains aspects de mon déploiement, mais en plus pour les expliquer dans un billet dédié.
Mais si vous avez fait une installation classique en suivant les consignes avec un hyperviseur Xen dessus (pas la peine de suivre toute la partie configuration réseau), c'est bien aussi.
C'est bon ? Ok, nous pouvons donc passer aux choses sérieuses !
Configuration réseau du Dom0
Y'a pas, j'ai beau retourner le billet dans tous les sens, on en revient à la configuration réseau à un moment, vu que c'est un peu Ze point technique qui fait que je m'[CENSURE] à rédiger ce billet......
Renommage des interfaces
Avec la nouvelle version de Debian, je me retrouve avec des noms d'interfaces modernes, prédictibles et poétiques comme "ens160" ou "enp11s0f1"...... ok, c'est stable même si on joue au bonneteau avec les interfaces réseau, mais pour s'y retrouver quand on est connecté en ssh sur le serveur pour vérifier un truc sur le réseau, c'est ....... enfin, c'est pas ....... disons que je ne suis pas hyper fan.....
Depuis quelques années sur d'autres installations, j'étais habitué à modifier le quasi magique /etc/udev/rules.d/70-persistent-net.rules...... Sauf que sur mon installation toute fraiche de Debian Stretch, il n'existe plus par défaut, le script tout aussi magique /lib/udev/write_net_rules qui est censé le fabriquer n'existe plus non plus, et les explications à propos de fichiers /etc/systemd/network/xx-nom.link ne fonctionnent pas non plus (je n'ai pas trop creusé pourquoi).
La seule solution qui fonctionne dans mon cas a donc été de recréer manuellement un /etc/udev/rules.d/76-netnames.rules (le numéro et le nom doivent venir du nième lien sur lequel j'ai cliqué pendant mes essais et reboots.......):
SUBSYSTEM=="net", ACTION=="add", ATTR{address}=="ma:ca:dd:re:ss", NAME="ethlan1"
Vous noterez le nom: autant je ne suis donc vraiment pas fan des nommages prédictibles mais pas pratiques du tout, autant nous allons avoir ici pas mal d'interfaces réseau différentes, du coup, quitte à les renommer, autant utiliser des noms qui me permettront par la suite de facilement m'y retrouver, quitte à avoir des noms un peu plus longs. Donc toutes mes interfaces auront un nom du genre "type" "fonction" "numéro optionnel".
Donc là, c'est une interface ethernet (eth), que j'utiliserai pour mon LAN, et je prévois d'en avoir au moins 2, donc je lui colle le numéro 1.
J'utiliserai cette convention dans tout le reste du billet sans forcément détailler à chaque fois.
Un cycle complet sera une série de 100 La ligne est bien sur à reproduire et à ajuster autant de fois que d'interfaces à renommer. Les adresses MAC sont à priori les identifiants les plus fiables pour correctement repérer les interfaces réseau, jusqu'au jour où on en rajoutera une, bien sur !
Voilà, il ne reste donc plus qu'à brancher un RJ45 sur chaque prise, repérer quelle interface a été détectée comme ayant un link up, noter son adresse MAC et mettre à jour dans le fichier......... Un petit reboot plus tard et j'ai plein de jolies interfaces avec des noms stables ET compréhensibles pour moi !
Un peu de config pour améliorer le débit
Fût un temps où je vous aurais donné la conf en 24,359 fois (et la 17eme vous aurait vraiment étonné !) et vraiment vraiment en kit. Sans aller jusqu'à dire qu'il vous suffit ici de copier/coller pour que tout fonctionne, je vais de suite poser une info simple: on va passer le MTU à 9000 partout, vu que le support des Jumbo Frames est désormais annoncé comme fonctionnel dans Xen. Avec un test simple (iperf) entre 2 VMs qui traversent le firewall (configuré en mode "laisse passer, cherche pas à analyser"), le simple fait de passer le mtu à 9000 (sur l'ensemble du chemin !!!) permet d'avoir plus ou moins x2 en performances.....
Voilà, voilà....... et à la fin, le Titanic coule.....
/etc/network/interfaces.d
Sur une ancienne version de ma configuration, je me suis retrouvé avec un /etc/network/interfaces difficile à maintenir. Et sur la nouvelle, le nombre total d'interfaces est plus élevé...
Du coup, pour cette nouvelle configuration toute vierge et encore un peu naïve, j'ai décidé de faire propre en utilisant quelques possibilités de ce fichier de configuration:
D'abord, nous allons utiliser les fonctions d'héritage de configuration. Pour prendre un exemple simple qui ne spoile pas trop la suite (parce que c'est pas du tout mon genre, de spoiler la suite):
iface ethtemplate inet static
mtu 9000
iface ethlan1 inet manual inherits ethtemplate
Isolé, cet exemple ne sert pas à grand chose. Mais en rajoutant quelques autres options de configuration au template, et en se souvenant que nous allons avoir plus de 20 interfaces réseau qui vont utiliser ça, si un jour je veux modifier globalement le MTU de toutes mes interfaces (par exemple si je me rends compte à la fin que c'est encore un peu ambitieux d'utiliser les Jumbo Frames sous Xen ?), je serai content d'avoir utilisé un template !
Cet héritage a également grandement simplifié la version openvswitch de ma configuration, surtout quand j'ai découvert qu'il était possible de faire de l'héritage d'héritage. J'avais alors un truc dans le genre:
iface ovs_eth_template inet manual
[de la conf très générique pour toutes mes ethernet]
iface bridgespecial_t template inet manual inherits ovs_eth_template
ovs_bridge bridgespecial
iface ethmembredubridge1 inet manual inherits bridgespecial_t
iface ethmembredubridge2 inet manual inherits bridgespecial_t
iface ethmembredubridge3 inet manual inherits bridgespecial_t
iface ethmembredubridge4 inet manual inherits bridgespecial_t
(parce que forcément, quand il y a une seule interface, c'est un peu moins pertinent.....).
Ensuite, presque tout sera réparti dans de petits fichiers posés dans /etc/network/interfaces.d, à part la configuration du loopback. Les configurations de templates auront des noms de fichiers qui commenceront par 00- (1 fichier par template), et ensuite les autres éléments de configuration seront groupés par bloc logique, également avec des préfixes numérotés pour s'assurer de l'ordre de configuration.
Enfin, plus pour faire joli qu'autre chose, et comme le nommage de mes interfaces me permettra de le faire, il y aura de temps en temps des utilisations d'expressions régulières.
Ca y est, on peut faire la conf réseau, maintenant ?
Oui, on peut, et même qu'on va le faire. Bien évidemment, chaque configuration réseau est unique, voyons donc un peu les différents cas de figures possibles, après libre à vous d'assembler comme il vous plaira.
My name is Bond.....
Ne vous plaignez pas du titre approximatif de cette section, avec un peu d'imagination vous pourrez trouver par vous même à quoi de pire vous avez échappé......
Le principe du bonding, également connu en tant que LACP ou IEEE_802.3ad, comme nous l'avons vu au dessus, est de regrouper plusieurs interfaces ethernet pour n'en faire qu'une seule virtuelle. Les avantages sont en particulier d'avoir un lien qui continue de fonctionner en cas de problème sur l'un des liens (câble coupé, interface défectueuse, etc.....), et pouvoir répartir (plus ou moins efficacement) la bande passante entre les interfaces. A ne pas confondre avec le principe du bondage, donc, qui parle de liens aussi, mais dont le but n'est pas le même !
La répartition de charge est cependant surtout efficace sur de multiples petites connexions de nombreuses sources/destinations différentes. Autant dire que dans mon cas, sur 4 liens, si j'arrive de temps en temps à en utiliser un peu 2, c'est déjà magnifique...... Je parle bien à nouveau du bonding.........
Mais nous n'allons pas nous arrêter pour si peux, et nous allons configurer une interface de type bond, dans /etc/network/interfaces/05-bondlink:
auto ethbond0 ethbond1 ethbond2 ethbond3 auto bondlink iface ethbond0 inet manual iface ethbond1 inet manual iface ethbond2 inet manual iface ethbond3 inet manual iface bondlink inet manual slaves ethbond0 ethbond1 ethbond2 ethbond3 bond_mode 802.3ad lacp_rate fast bond_miimon 100 bond_updelay 100 xmi_hash_policy layer2+3 mtu 9000
J'aurais bien aimé mettre une expression régulière pour slaves, vu que j'ai intelligemment nommé mes interfaces, mais je n'ai pas trouvé de syntaxe qui fonctionne (si quelqu'un a, ça m'intéresse !).
Les options suivantes sont là pour paramétrer plus précisément le mode d'agrégation de lien, vous pouvez les copier comme des sauvages ou aller lire la documentation pour déterminer quels paramètres vous voulez utiliser. Il est important d'utiliser les mêmes paramètres (en particulier la policy et le bond_mode) sur l'équipement en face !
Je n'ai pas installé le package "ifenslave" (et d'ailleurs, l'exécutable ifenslave est un script qui fait essentiellement passe-plat vers le binaire ip), et pourtant mon interface bondlink s'active correctement.
C'est peut être les soldes, mais j'ai aussi une interface bond0 qui traîne, alors qu'elle n'existe nulle part dans ma configuration (et le fait d'installer le package ifenslave n'y changera rien) !
Je n'utilise pas le template eth, qui sert pour l'instant seulement à fixer le MTU: c'est du coté de l'interface de bonding qu'il faut mettre le MTU à 9000, et c'est reporté automatiquement à toutes les interfaces.
Je n'ai pas créé non plus de template pour les interfaces de bonding, vu que je vais avoir une seule configuration de ce type sur mon serveur, mais si vous avez prévu d'en avoir plusieurs, vous pouvez bien évidemment regrouper la plupart des paramètres dans un template dédié.
D'après la doc, il y a d'autres possibilités de "bond_mode", pas forcément standardisées, mais qui pourrait être intéressantes si vous avez également un Linux en face (qui connaît ces modes, du coup).
Voilà, nous avons maintenant 4 interfaces agrégées en LACP..... sans IP, voyons tout de suite pourquoi.......
Bridges ethernet
Mais quelle transition magique !!!!
Chaque interface ou groupe d'interface (un LACP, par exemple.....) physique sera mise à disposition séparément de la VM firewall via un bridge (littéralement, un pont, donc) dédié. Les interfaces ou groupes n'auront donc jamais d'IP configurée: c'est ainsi que fonctionne une configuration réseau sous Linux, les IPs sont portées par les interfaces bridge (ce qui me parait assez logique, en fait.....).
La plupart des bridges n'auront pas non plus d'adresse IP pour autant: le Dom0 fait uniquement passe-plat (enfin, passe-paquets) entre des RJ45 (ou d'autres VMs) et les interfaces réseau du firewall. Voyons ca.....
Le cas de figure le plus basique est celui d'un bridge sans interfaces ethernet, qui est créé pour que des interfaces virtuelles (celles des VMs, donc) puissent plus tard y être raccrochées.
Par exemple, mon /etc/network/interfaces.d/80-brvpub (le bridge des VMs publiques) contient:
auto brvpub iface brvpub inet manual inherits brtemplate bridge_ports none
La dernière ligne sert à bien confirmer que non, on est pas de gros boulets qui ont oublié la conf, oui on veut vraiment démarrer un bridge qui pour l'instant n'a aucune interface, merci: que ce soit le firewall ou les serveurs de l'autre coté, c'est dans la configuration des VMs que sera indiqué le fait de raccorder leurs interfaces virtuelle (vif) à ce bridge en particulier, pour une raison bien simple: ces interfaces n'existent pas encore au moment de la création du bridge !
Nous aurons le même cas dans tous les exemples ci-dessous, vous serez du coup bien aimables de revenir à chaque fois relire la ligne ci-dessus pour avoir l'explication, qui est la même.....
A peine plus complexe, un bridge qui relie (pour l'instant, donc) une seule interface ethernet. Voyons le contenu de /etc/network/interfaces.d/50-guest (une interface réseau dédiée chez moi aux équipements "invités", donc):
auto ethguest auto brguest iface ethguest inet manual inherits ethtemplate iface brguest inet manual inherits brtemplate bridge_ports ethguest
Notez que ici, c'est dans le ethtemplate qu'il y a la configuration du MTU: le bridge prendra toujours forcément le plus petit MTU parmi les interfaces qui le composent.
Nous allons également créer le bridge dédié pour le LACP créé juste avant (oui, au début du billet, il devait être regroupé avec des interfaces en switch, mais au final, j'ai décidé de le mettre sur un bridge dédié, il n'y a que les imbéciles qui ne changent pas d'avis, je l'ai toujours dit et je n'en démordrai pas !), en rajoutant à la fin de /etc/network/interfaces/05-bondlink:
auto brbond iface brbond inet manual inherits brtemplate bridge_ports bondlink
Et pour finir, nous allons "exploiter" le bloc de 8 interfaces pour créer un switch au niveau de l'hyperviseur, via /etc/network/interfaces/10-switch:
auto ethsw1 ethsw2 ethsw3 ethsw4 ethsw5 ethsw6 ethsw7 ethsw8 auto brswitch iface ethsw1 inet manual inherits ethtemplate iface ethsw2 inet manual inherits ethtemplate iface ethsw3 inet manual inherits ethtemplate iface ethsw4 inet manual inherits ethtemplate iface ethsw5 inet manual inherits ethtemplate iface ethsw6 inet manual inherits ethtemplate iface ethsw7 inet manual inherits ethtemplate iface ethsw8 inet manual inherits ethtemplate iface brswitch inet manual inherits brtemplate bridge_ports regex ethsw.*
A mon grand regret, le seul endroit où j'ai réussi à trouver une syntaxe de gestion d'expressions régulières, c'est pour le bridge_ports. J'aurais aimé faire un truc genre:
auto ethsw.* iface ethsw.* inet manual inherits ethtemplate
mais ca ne fonctionne pas (en tout cas sur ma version actuelle !), et mes recherches sur le net pour trouver une autre syntaxe permettant ce genre de choses sont restées infructueuses......
Si vous voulez finalement faire quand même un bridge qui regroupe switches et LACP, c'est facile: il suffit de configurer chaque LACP séparément, et vous pourrez finir par:
iface brenorme inet manual inherits brtemplate bridge_ports bondana bondjames ethsw1 ethsw2 ethsw3 ethsw4
On doit même pouvoir faire un truc classouille avec les regex, mais j'ai la flemme de faire des essais pour une configuration que je n'utiliserai finalement pas dans la vraie vie......
On pourrait accélérer le démarrage, stp ?
Oui, on l'avait à vrai dire déjà vu dans l'épisode précédent, ca met un temps fou à démarrer, à cause du Spanning Tree Protocol, STP, donc... Il suffit de le désactiver en indiquant dans le template de bridge:
iface brtemplate inet manual
bridge_stp 0
bridge_waitport 0
bridge_fd 0
Ah, et donc, assurez vous de ne pas faire de boucles réseau, vu que vous venez de désactiver le truc qui les aurait détectées et plus ou moins gérées pour vous.........
Bypass de netfilter
A la création de chaque vif, les scripts Xen rajoutent des entrées de forwarding dans iptables, du genre:
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 PHYSDEV match --physdev-out vifxx --physdev-is-bridged 0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 PHYSDEV match --physdev-in vifxx --physdev-is-bridged
Mais dans notre cas, l'analyse des paquets en transit est le boulot de la VM firewall, donc nous allons nous assurer que la pile IP de l'hyperviseur en fait le moins possible, en rajoutant ces 3 lignes dans /etc/sysctl.conf (ou dans un fichier dédié de /etc/sysctl.d si vous voulez faire propre..... ce qui est mieux......):
net.bridge.bridge-nf-call-ip6tables = 0 net.bridge.bridge-nf-call-iptables = 0 net.bridge.bridge-nf-call-arptables = 0
Sur les versions relativement récentes des noyaux Linux, il sera également nécessaire de forcer le chargement du module br_netfilter au démarrage:
echo br_netfilter >> /etc/modules
(là aussi, vous pouvez faire un fichier dédié dans /etc/modules-load.d)
Petit reboot (ou actions équivalentes à la main si vous préférez), et on pourra constater que les paquets qui doivent transiter sur les bridges circulent sans soucis, même avec un ip_forward=0 au niveau de la configuration de l'hyperviseur, même avec une configuration de filtrage en BLOCK/DROP.
On pourrait du coup aller modifier les scripts de Xen pour qu'il ne génère pas les règles de forward.
Un peu d'isolation réseau.....
A ce moment de la configuration, que ca soit avec bridge ou avec openvswitch, j'ai des bridges sans IP qui se permettent de répondre à des requêtes ARP avec leur propre adresse MAC, ce qui fout rapidement un sacré bordel dans le réseau..... Si j'en crois ce que j'ai lu ici, le problème vient du noyau Linux, qui a une notion pas très exclusive des couples Adresse MAC / Adresse IP correspondante. Sur le principe, tant que c'est entre adultes consentants et fait de façon safe, je ne suis pas le genre de gars à critiquer ce genre de relations libres, sauf que là, justement, ca n'est pas safe du tout, il faut donc y remettre un peu d'ordre.
La solution proposée par Vincent (oui, style genre on est potes de longue date, alors que j'ai découvert son blog il y a quelques jours) est d'activer une fonctionnalité relativement récente du noyau Linux, qui est le filtrage des VLANs sur les ports d'un bridge (je ne fais quasiment que recopier.......). Comme je n'aime pas appliquer une commande sans comprendre ce qu'elle active vraiment, j'ai cherché un peu d'autres infos sur cette fonctionnalité, et à peu près à chaque fois, ca parlait de vraiment faire passer des VLANs sur un bridge, ce qui n'est pas du tout mon cas d'usage.
Toujours d'après Vincent, ebtables n'a pas l'air d'être une solution méga fiable, donc j'ai un peu mis de coté.
A un moment je vais arrêter de citer Vincent, mais pas encore là maintenant de suite, il évoque aussi la possibilité de résoudre le truc avec tc(8). Ce truc a l'air bien, faudra que je regarde......
En pratique, j'ai résolu au moins la partie émergée de mon problème avec une commande assez simple:
ip link set <dev> arp off
Et ce, sur toutes mes interfaces qui n'ont pas d'adresse IP. C'est à dire à peu près toutes mes interfaces, donc, sauf celle d'admin et le loopback.
Pour les bridge et les ethernet, il suffit de modifier les templates, qui deviennent:
iface brtemplate inet manual
bridge_stp 0
bridge_waitport 0
bridge_fd 0
post-up ip link set $IFACE arp off
iface ethtemplate inet manual
mtu 9000
post-up ip link set $IFACE arp off
Et donc, on fera attention à bien déshériter l'interface d'admin et le loopback, en espérant qu'ils ne fassent pas de procès.......
Pour les vif, je n'ai pas trouvé mieux que modifier /etc/xen/scripts/xen-network-common.sh, et en particulier _setup_bridge_port():
--- /etc/xen/scripts/xen-network-common.sh
+++ /etc/xen/scripts/xen-network-common.sh
@@ -92,6 +92,8 @@ _setup_bridge_port() {
# stolen by an Ethernet bridge for STP purposes.
# (FE:FF:FF:FF:FF:FF)
ip link set dev ${dev} address fe:ff:ff:ff:ff:ff || true
+ ip link set dev ${dev} arp off mtu 9000 || true
+ ethtool -K ${dev} tx off gso off gro off tso off
fi
# ... and configure it
@@ -133,6 +135,7 @@ add_to_bridge () {
# Usage: set_mtu bridge dev
set_mtu () {
+ return
local bridge=$1
local dev=$2
mtu="`ip link show dev ${bridge}| awk '/mtu/ { print $5 }'`"
Notez que je ne suis pas tout à fait certain que tout ceci soit vraiment nécessaire: il suffit peut être de mettre cette option uniquement sur les bridges. Mais il n'y a vraiment vraiment aucune raison pour que le noyau s'occupe de quoi que ce soit lié à ARP (voire même de quoi que ce soit en général, d'ailleurs) sur ces interfaces, donc autant le lui dire. Et j'en profite pour glisser aussi une MTU à 9000 sur ces interfaces, n'ayant pas trouvé de méthode qui fonctionne via /etc/network/interfaces pour le faire. Et je désactive donc la fonction set_mtu(), qui ne réagit pas correctement dans le cas d'un bridge qui n'a pas déjà un MTU à 9000 (donc un bridge sans interface physique avec un MTU à 9000, soit plus de la moitié de mes bridges.....).
Je désactive aussi des trucs avec ethtool, l'explication est plus bas, et comme je suis un gars cool je vous livre le patch en une seule fois......
Un peu plus d'isolation réseau
A priori, ca ne devrait pas être nécessaire avec toute cette configuration, et c'est le rôle de la VM firewall d'assurer la sécurité réseau, mais un vieux dicton dit Ceinture, bretelles et calecon propre
, donc je vais mettre en place un petit script de filtrage, qui autorise en entrée le ssh, le NTP et le ping:
#!/bin/sh ADMINIF=bradmin IPTABLES=/sbin/iptables # Set filter default policies to "Drop" # Done first for security reasons $IPTABLES -t filter -P INPUT DROP $IPTABLES -t filter -P FORWARD DROP $IPTABLES -t filter -P OUTPUT DROP $IPTABLES -t filter -F INPUT $IPTABLES -t filter -F OUTPUT # Creating table for Established / related packets. # Create Table $IPTABLES -t filter -N stateful $IPTABLES -t filter -F stateful # Accept all related packets $IPTABLES -A stateful -m state --state ESTABLISHED -p tcp ! --syn -j ACCEPT $IPTABLES -A stateful -m state --state ESTABLISHED -p udp -j ACCEPT $IPTABLES -A stateful -m state --state ESTABLISHED -p icmp -j ACCEPT $IPTABLES -A stateful -m state --state RELATED -j ACCEPT $IPTABLES -A stateful -m state --state INVALID -j NFLOG --nflog-threshold 20 --nflog-prefix "Fw: invalid state" $IPTABLES -A stateful -m state --state INVALID -j DROP $IPTABLES -A INPUT -i lo -j ACCEPT $IPTABLES -A INPUT -j stateful $IPTABLES -A INPUT -p tcp -i $ADMINIF --dport 22 --syn -j sshguard $IPTABLES -A INPUT -m state --state NEW -p tcp -i $ADMINIF --dport 22 --syn -j ACCEPT $IPTABLES -A INPUT -m state --state NEW -p udp -i $ADMINIF --dport 123 -j ACCEPT $IPTABLES -A INPUT -m state --state NEW -p icmp -i $ADMINIF -j ACCEPT $IPTABLES -A OUTPUT -o lo -j ACCEPT # for the moment, allow all traffic from this host $IPTABLES -A OUTPUT -j stateful $IPTABLES -A OUTPUT -m state --state NEW -j ACCEPT
Ce script sera appelé en post-up dans la configuration du bridge d'admin (et cette version suppose que vous avez sshguard d'installé, mais si ce n'est pas le cas cela générera juste une erreur à la création de la règle qui fait référence à la chaine sshguard, le reste fonctionnera normalement).
Ca y est, on est assez isolés, là ?
Dans le cas décrit par Vincent, probablement pas. Sauf que, dans notre cas, l'hyperviseur ne fait aucun boulot de routage. D'ailleurs, le routage est désactivé: net.ipv4.ip_forward et
net.ipv6.conf.all.forwarding sont à 0.
Du coup, une tentative de routage forcée consommera probablement quelques cycles CPU en trop avant de se faire jeter dehors, mais entre le routage désactivé, le script de filtrage et la désactivation de tout ce qui est ARP presque partout, je n'ai pas réussi à faire passer des paquets en douce en utilisant les techniques décrites par Vincent (ou en tentant quelques autres variantes).
La VM Firewall
Voilà son fichier de configuration:
name = "Firewall"
builder = 'hvm'
vcpus = 2
maxvcpus = 2
cpu_weight = 256
memory = 1024
maxmem = 1024
#on_poweroff = "restart"
on_watchdog = "restart"
on_crash = "restart"
on_reboot = "restart"
disk = [ 'file:/home/Xen/Firewall.img,hda,w' ]
usb = 0
vif = [
'type=vif,vifname=vfwout,bridge=brout, mac=00:16:3e:xx:yy:0',
'type=vif,vifname=vfwlan,bridge=brlan, mac=00:16:3e:xx:yy:1',
'type=vif,vifname=vfwserver,bridge=brserver, mac=00:16:3e:xx:yy:2',
'type=vif,vifname=vfwswitch,bridge=brswitch, mac=00:16:3e:xx:yy:3',
'type=vif,vifname=vfwpub,bridge=brvpub, mac=00:16:3e:xx:yy:4',
'type=vif,vifname=vfwwifi,bridge=brwifi, mac=00:16:3e:xx:yy:5',
'type=vif,vifname=vfwbond,bridge=brbond, mac=00:16:3e:xx:yy:6',
'type=vif,vifname=vfwadmin,bridge=bradmin, mac=00:16:3e:xx:yy:7',
]
serial = 'pty'
Même avec le passage au toolstack xl, pas beaucoup de différence avec l'ancienne configuration.
Quitte à mettre des noms prédictibles, stables et explicites à toutes les interfaces réseau de la configuration, autant le faire aussi avec les vif créées, via l'argument vifname=.
00:16:3e: est toujours le préfixe MAC (à peu près rien à voir avec l'ordinateur homonyme de ma soeur, sauf que son MAC a une MAC, et même probablement 2......) réservé pour XEN, vous mettez ce que vous voulez pour xx:yy (mais je vous conseille cependant fortement de mettre des valeurs hexadécimales valides..... et je vous conseille aussi de mettre la même valeur xx:yy pour toutes les lignes, ainsi que de numéroter le dernier octet dans l'ordre, mais là c'est plus pour faire joli et s'y retrouver facilement).
Chaque interface est donc reliée à un bridge différent, et avec les jolis noms de bridges utilisés avant, ca en devient assez lisible.
L'ancienne configuration précisait model=e1000, la nouvelle type=vif, pour des raisons de performances: la VM doit tourner en HVM (virtualisation complète), mais embarque les drivers "PV-HVM" de Xen qui sont plus efficaces qu'un mode complètement émulé (type=ioemu, ce qui est le cas par défaut, et model=e1000, qui est un driver assez efficace quand même en mode ioemu).
Le fichier de conf d'une VM
Là, on est dans du assez simple, la partie réseau de la conf d'une VM classique ressemblera à ça:
vif = [
'vifname=vifnomdemavm,bridge=brnomdemavm,mac=00:16:3e:00:00:00',
]
Vous penserez à mettre autre chose que 00:00:00 à la fin de la MAC, et vous ajusterez le nom de l'interface et du bridge. Notez qu'il est bien sur possible de raccorder plusieurs VMs sur un seul bridge si besoin est.
accélération réseau et vifs
J'avais déjà eu le problème lors de mes anciennes installations: TCP Segmentation Offload et ses potes ne font pas trop bon ménage avec les interfaces Vif...
Ca semblait mieux sur mes premiers tests, mais mes interfaces étaient à ce moment toutes raccordées à des bridges qui contenaient aussi une interface ethernet (disposant elle d'un support de ces accélérations). Et dans mes premiers tests, laisser le support de ces trucs faisait gagner en performances, du coup, cette fois, j'ai essayé de ne pas être aussi bourrin qu'il y a quelques années, et j'ai fait quelques autres essais pour mieux comprendre...... J'ai cru à un moment pouvoir laisser activé l'accélération matérielle sur les bridges qui incluaient une interface ethernet physique. Si ca peut vous aider, j'avais alors fait cette modification (version openvswitch), qui profite du nommage de mes interfaces pour pouvoir déterminer facilement si une ethernet fait partie du bridge:
--- /etc/xen/scripts/vif-openvswitch.old
+++ /etc/xen/scripts/vif-openvswitch
@@ -79,6 +79,12 @@ add_to_openvswitch () {
local vif_details="$(openvswitch_external_id_all $dev)"
+ # check if a physical ethernet is connected to the bridge
+ local breth="$(ovs-vsctl list-ifaces $bridge |grep '^eth')"
+ if [ -z "$breth" ]; then
+ ethtool -K $dev tx off gso off gro off tso off
+ fi
+
do_or_die ovs-vsctl --timeout=30 \
if-exists del-port $dev \
-- add-port "$bridge" $dev $tag_arg $trunk_arg $vif_details
Il y a probablement moyen de l'écrire de façon plus classouille.......
Sauf que ca ne fonctionne toujours pas dans tous les cas: en particulier, chez moi, l'interface d'administration de l'hyperviseur embarque une interface ethernet (pour faire de l'administration réseau urgente avec un portable et un RJ45 si besoin est), mais les paquets émis localement passent par l'interface Vif en fonctionnement normal. Et mon hyperviseur s'est retrouvé joignable en ping, mais ni en TCP, ni en UDP......
J'en suis donc revenu à une désactivation systématique de la fonction sur les vifs, en allant remodifier _setup_bridge_port() dans /etc/xen/scripts/xen-network-common.sh (extrait du patch précédent):
--- /etc/xen/scripts/xen-network-common.sh.old
+++ /etc/xen/scripts/xen-network-common.sh
@@ -92,6 +92,8 @@ _setup_bridge_port() {
# stolen by an Ethernet bridge for STP purposes.
# (FE:FF:FF:FF:FF:FF)
ip link set dev ${dev} address fe:ff:ff:ff:ff:ff || true
+ ip link set dev ${dev} arp off mtu 9000 || true
+ ethtool -K ${dev} tx off gso off gro off tso off
fi
# ... and configure it
Au début, j'avais aussi tenté de désactiver rx (vérification du checksum en réception), mais il ne semble pas désactivable, et ca ne semble pas poser de problèmes...... Sur le coup, je n'ai apparemment même pas besoin de faire les mêmes désactivations dans mes VMs (à part le firewall, mais c'est fait automatiquement), ce qui m'arrangera quand je ferai d'autres installations en vraies conditions de prod (donc en utilisant le réseau dès l'installation).
Après mes premiers vrais benchs, je me suis retrouvé avec des vif désactivées dans le Dom0 et le message suivant dans le dmesg:
vif vif-xxx viftruc: txreq.offset: 18, size: 9014, end: 9032 vif vif-xxx viftruc: fatal error; disabling device
En cherchant une nouvelle fois un peu sur le net, en faisant quelques essais et en redémarrant à chaque fois la VM concernée par l'interface bloquée (je n'ai pas trouvé mieux comme solution pour réactiver ces interfaces), j'ai fini par constater que le problème ne se pose plus si je fais la même commande ethtool sur les interfaces des VMs. Et vu ce que j'ai eu le temps de mesurer avant d'avoir ces désactivations d'interfaces, les différences de performances sont à peu près inexistantes.
Edit: Après quelques mois d'utilisation, en fait, le problème arrive toujours de temps en temps. Les dernières fois où c'est arrivé, c'était lors d'un classique apt install <un truc>. J'ai eu le même problème en installant le même paquet sur 2 VMs différentes, mais le plantage n'a pas eu lieu sur le même paquet de dépendance en cours de téléchargement. En général, il me suffit d'effacer le paquet "partial" (qui avait fait planter) et de relancer le apt install pour que ça fonctionne. Par contre, une fois, je n'ai pas effacé le partial et relancé le apt install, et j'ai eu à nouveau le problème.
Enfin, quand je dis "il suffit de", ce n'est pas tout à fait vrai: je dois d'abord récupérer une interface fonctionnelle coté hyperviseur ! Si j'en crois ce que j'ai dit dans la première version de ce billet, je pouvais apparemment la récupérer juste en redémarrant la VM. Peut être à cause du nommage des interfaces, je me retrouve maintenant à devoir redémarrer l'ensemble de l'hyperviseur pour récupérer l'interface fonctionnelle, ce qui est franchement désagréable !
Même stoppant complètement la VM, en renommant son interface dans le .xl et en la redémarrant, je ne récupère pas l'interface coté hyperviseur.....
Démarrage et redémarrage....
ordre de démarrage des VMs
En prod, au moins la VM firewall doit démarrer automatiquement. Dans mon cas, la plupart des autres VMs aussi. En plus, certaines VMs peuvent dépendre d'autres au niveau du réseau. Par expérience sur mes anciens hyperviseurs, je réduis au maximum les dépendances réseau de mes VMs au démarrage: pas de DHCP, montages NFS en autofs ou équivalent, etc.... Il est cependant également possible de spécifier l'ordre de démarrage des VMs, en s'assurant de l'ordre des fichiers dans /etc/xen/auto (faites comme tout le monde, mettez des numéros au début des noms de vos fichiers).
Le réseau que vous demandez n'est pas encore disponible....
Dans ma version actuelle, tout fonctionne, mais pas au boot: les VMs ne démarrent pas, et en creusant un peu, c'est tout simplement parce que les bridges ne sont pas encore prêts au moment où le système veut démarrer les VMs. Après avoir creusé un peu, j'ai trouvé une solution assez simple qui consiste à préciser que le démarrage des domaines Xen nécessite un réseau déjà établi:
--- /etc/init.d/xendomains.old +++ /etc/init.d/xendomains @@ -1,8 +1,8 @@ #!/bin/bash ### BEGIN INIT INFO # Provides: xendomains -# Required-Start: $syslog $remote_fs xen -# Required-Stop: $syslog $remote_fs xen +# Required-Start: $syslog $remote_fs xen $network +# Required-Stop: $syslog $remote_fs xen $network # Should-Start: drbd iscsi openvswitch-switch # Should-Stop: drbd iscsi openvswitch-switch # X-Start-Before: corosync heartbeat libvirtd
A propos de réseau pas disponible et de boot, dans ce genre de configurations, pensez à vérifier le contenu de /etc/network/if-up.d (et if-pre-up.d): dans mon cas, après avoir installé openntpd, je me suis retrouvé avec un script de redémarrage du démon à chaque activation d'interface réseau...... j'ai plus de 80 interfaces réseau, dont 30 activées pendant le démarrage...........
Redémarrage de l'hyperviseur
Par défaut, lors de l'arrêt de l'hyperviseur, les scripts (au moins chez Debian ?) stoppent les VMs dans l'ordre inverse de démarrage (la plus récemment démarrée en premier, donc). L'idée n'est pas mauvaise, jusqu'au moment où vous allez vouloir redémarrer une VM, pour une raison ou une autre..... Après quelques bricolages, j'en suis arrivé à la conclusion que le plus simple serait d'intercepter le script /usr/lib/xen-common/bin/xen-init-list (appelé par les scripts d'arrêt des domaines Xen) pour changer l'ordre de son affichage. Pour l'instant, je n'ai pas encore de solution générique propre, du coup il n'y a pas d'intérêt à partager mon bricolage qui ne fonctionne que chez moi.........