Disclaimer
Comme pour à peu près n'importe quel billet de la catégorie "Vieux con de hacker old school", ce billet parle de trucs techniques. J'ai glissé des liens ici et là pour que ma sœur puisse presque suivre les très grandes lignes (les autres personnes peuvent aussi cliquer, je suis de bonne humeur aujourd'hui), mais je n'expliquerai pas la plupart des concepts en détails.
Comme pour à peu près n'importe quel billet de la catégorie "Vieux con de hacker old school", tout ceci a été fait par un Vieux con de hacker old school (ah mais c'est donc ça l'explication du nom de la catégorie !!!!!!), dans des conditions de sécurité optimales, sur des machines consentantes, avec un vrai réseau de prod fonctionnel à coté pendant tout le temps de la préparation pour pouvoir aller buller sur facebook chercher les infos au fur et à mesure des problèmes qui se sont posés.
Comme pour à peu près n'importe quel billet de la catégorie "Vieux con de hacker old school", il n'y aura aucune photo de chaton dans ce billet. Il n'y aura d'ailleurs probablement pas du tout de photo, image ou tout autre truc du genre.......
Comme pour à peu près n'importe quel billet de la catégorie "Vieux con de hacker old school", libre à vous de suivre les indications de ce billet pour reproduire la même chose chez vous, je n'essaierai même plus de vous en dissuader, mais ne venez pas vous plaindre en cas de désagrément plus ou moins douloureux pour vos données, voire pour votre intégrité physique (et je ne veux pas savoir comment c'est arrivé dans ce cas !).
Comme pour à peu près n'importe quel billet de la catégorie "Vieux con de hacker old school", il y a très peu de chances pour que le contenu de ce billet vous aide d'une quelconque façon à pecho en boite.......
Comme pour n'importe quel billet de la catégorie "Vieux con de hacker old school", aucun animal mignon n'a été blessé, tué ou mangé pendant la réalisation des opérations.
Le contexte
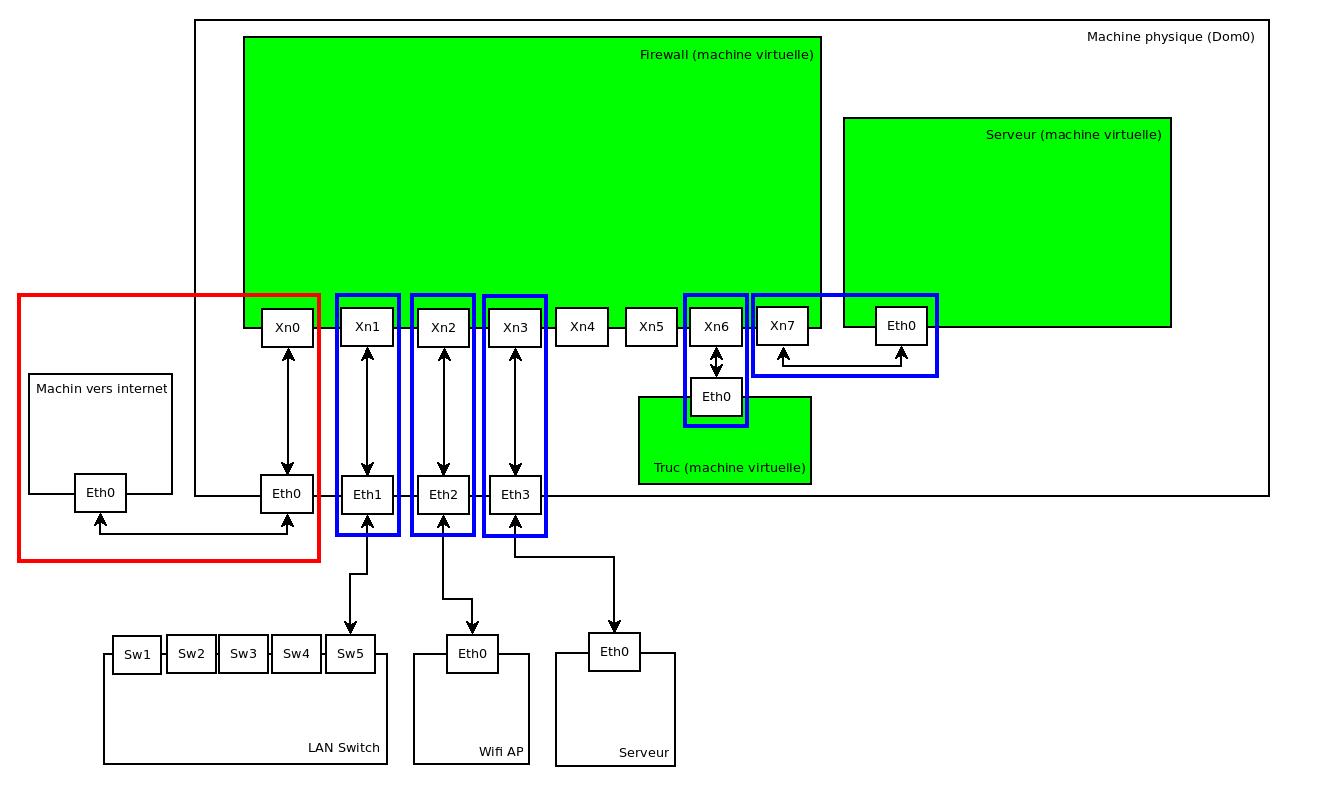
Jusqu'à présent, j'avais toujours séparé mon NAS et mon hyperviseur Xen. Du coup, d'un coté, j'avais un serveur avec de gros disques (pour l'époque) en RAID miroir dédiés au stockage de mes photos données et peu d'autres contraintes, à coté un autre serveur (aussi avec des disques en RAID miroir, mais nettement plus petits) qui faisait tourner plusieurs machines virtuelles. Les problématiques étaient donc distinctes.
Un hyperviseur pour les gouverner tous....
Mais j'ai entre temps récupéré (gratos, du coup ca serait dommage de se priver) un serveur un peu ancien mais cependant tout à fait apte à gérer l'ensemble:
- 2 sockets, 4 coeurs hyperthreadés par CPU, soit un total de 16 unités logiques de traitement d'après mon /proc/cpuinfo (nous ne débattrons pas ici de l'exactitude de ce calcul, en réalité j'ai bien 8 coeurs qui sont plus ou moins capables de chacun traiter 2 trucs en parallèle).
- Du SATA 2. Je n'ai pas le budget pour acheter des disques SSD de plusieurs To, donc j'utilise des disques mécaniques, donc le SATA 2 est suffisant d'un point de vue performances.
- 48Go de RAM. Bon, en vrai au départ, je n'avais que 8Go de RAM, ce qui est déjà correct, mais comme j'ai trouvé un lot de 6x8Go (de la DDR3 ECC Registered) à pas cher, j'en ai profité !
- 10 Interfaces Ethernet Gigabit (dont 4 en SFP), et un connecteur disponible pour venir brancher des cartes 10Gbs.....
Du coup, même mon NAS va passer en machine virtuelle (après quelques mesures de performances disques qui confirment que les débits depuis une VM sont quasi identiques à ceux depuis le Dom0), et mes anciennes stratégies d'utilisation des disques deviennent difficilement applicables....
En plus, je me retrouve à utiliser de très gros disques (8To) sur un serveur dont le BIOS est un peu ancien, ce qui m'a posé quelques petits problèmes supplémentaires.
Un peu de stratégie en amont....
Une des questions existentielles qu'on se pose quand on déploie de nouveaux serveurs, c'est le partitionnement des disques.....
Jusqu'à présent, j'avais toujours utilisé des partitionnements assez classiques: un MBR, une partition principale pour le système de base, et une partition étendue qui contient le reste, dont un /usr en lecture seule avec de la marge pour d'éventuelles installations ultérieures d'outils/services/etc...., très souvent un /var séparé, un /tmp soit en RAMFS soit en partition séparée également, et un /home qui occupe tout le reste.
Sur un NAS dédié, ca fonctionne assez bien (on perd quelques Go sur quelques To, pas bien grave.....).
Sur mon ancien serveur de VMs, ca fonctionnait assez bien aussi, vu que toutes les VMs avaient leurs disques stockés en fichiers dans le /home.
Sur mon nouveau précieux serveur unique, c'est plus compliqué. Si j'avais décidé de laisser le /home géré par le Dom0, j'aurais pu rester plus ou moins sur ce modèle, mon /home gigantesque aurait stocké mes données ET les images de mes VMs. Sauf que, pour faire propre, l'hyperviseur ne fera vraiment pratiquement QUE hyperviser (il fera aussi ce qu'il est vraiment le seul à pouvoir faire, comme surveiller les disques, la température, et tant qu'à faire l'onduleur), donc le NAS sera assuré par une VM. Donc le gros /home de plusieurs To ne sera pas directement accessible par l'hyperviseur.
En vrai, là, j'aurais pu faire un truc un peu dégueulasse, genre un /home gigantesque sur le Dom0, et dedans une image presque aussi gigantesque utilisée par la VM qui fera le NAS....... Sauf que je veux un NAS qui dépote, et c'est vraiment une très très mauvaise base pour avoir de bonnes performances disques par la suite ! Accessoirement, j'aurais aussi eu la question de la taille de l'image: trop et je n'ai plus assez de place pour d'autres usages, pas assez et un jour je déborde sur cette partition (même si à priori, j'ai de la marge cette fois ci, mais je croyais déjà que c'était le cas sur les anciens disques de 2To.......).
Du coup, premier élément de solution: je vais (enfin ?) me mettre à utiliser Logical Volume Management, LVM pour les intimes (et on va rapidement devenir assez intimes.....). Dans mon cas, la possibilité d'ajouter des disques/partitions plus tard ne m'intéresse pas vraiment: j'ai déjà de la marge (enfin, pour l'instant), et surtout, parmi les rares contraintes de mon prochain serveur, je n'ai que 2 emplacements propres pour disques durs 3 1/2, qui seront donc d'entrée de jeu utilisés (par mes 2 disques de 8To en RAID miroir, pour les 2 du fond qui ne suivent pas.....).
Ce qui m'intéresse vraiment, c'est avant tout de pouvoir créer un volume logique ("logical volume", que nous appellerons simplement "lv" par la suite, ou "lvs" quand il y en aura plusieurs) avec une quantité d'espace allouée, et de pouvoir augmenter cet espace plus tard. Du coup, je n'alloue pas tout pour l'instant, et je pourrai rajouter un peu au fur et à mesure, là où ça sera nécessaire. Notez que, techniquement parlant, LVM permet aussi de faire l'inverse (réduire la taille d'un lv, et du système de fichiers dedans), mais c'est quand même plus ou moins déconseillé par plein de monde de faire dans ce sens......
Je suis un peu tenté aussi par d'autres fonctionnalités de LVM, comme la possibilité d'utiliser un disque SSD en cache pour le gros lv du /home, ou le fait de pouvoir faire des clichés (que nous appellerons "snaps" par la suite).
Mon plan de partitionnement se simplifie sacrément d'un coup: une énoooooorme partition entièrement dédiée à LVM, et je crée au fur et à mesure de mes besoins de petits lvs, pour le Dom0 comme pour les VMs. Bon, parmi ces "petits lvs", il y en aura un de plusieurs To dès le départ, mais l'idée reste la même, et à la fin de l'installation initiale, il y aura au moins 1 ou 2 TOs non alloués.
Il reste donc juste à organiser le partitionnement de chaque système.....
Diviser pour mieux régner
Le plus simple serait d'avoir une partition par système. Cette approche présente historiquement le gros avantage de ne pas trop se poser de questions de répartition d'espace entre les partitions, mais j'ai donc désormais LVM pour ne plus être coincé de ce coté là. En contrepartie, cette approche présente également au moins 2 problèmes potentiels:
Un /var/log ou un /tmp qui se remplissent trop peuvent saturer tout l'espace disque. Un /home aussi, mais dans mon cas, il est déjà fourni à part.
Comme les mêmes /var, /tmp et /home doivent être en lecture/écriture, tout le système doit l'être aussi. Or, avoir une partie de son système en lecture seule présente des avantages: réduction des risques d'erreurs de manipulation, (un peu) plus difficile pour un attaquant de poser durablement un rootkit ou équivalent, peu/pas de risques de casser le système de fichiers même en cas d'arrêt brutal du serveur. Bien sur, pour les opérations de maintenance (mises à jour, etc.....) on peut/doit repasser temporairement le système de fichiers en lecture/écriture.
Bref, je veux partitionner, et avoir une partie de mon système en lecture seule..... Dans un premier temps, du coup, j'ai envisagé de faire plein de partitions par système, comme d'habitude, dont /usr en lecture seule..... pour le Dom0, pas trop de problèmes, mais pour les VMs, c'est plus lourd: soit je crée un seul lv au niveau du Dom0, et je fais du LVM dans du LVM (le 2eme niveau étant géré au niveau de la VM), niveau perfs ca semble ne pas changer grand chose, mais le redimensionnement des lvs devient plus lourd. Soit je crée plein de lvs au niveau du Dom0, je passe tout ca à la VM, ca fait un fichier de conf Xen un peu compliqué, mais surtout ça va me compliquer la vie le jour où je voudrai faire des snaps de mes VMs !
Donc j'ai fait un état des lieux par répertoire. Je ne tiens pas compte des répertoires particuliers (/sys, /run, /dev, etc...... mais pas /etc !) qui sont de toutes façons gérés dynamiquement.
En gros, /var, /tmp, /root et /home doivent être en lecture/écriture. /root et /home contiendront très peu de données dans mon cas (un .bashrc, un .ssh/authorizedkeys et peut être 2-3 trucs temporaires de temps en temps). A vrai dire, une fois l'installation initiale d'un système terminée, le seul intérêt pour moi de les avoir dans la catégorie "lecture/écriture", c'est pour pouvoir enregistrer le .bashhistory........ du coup, j'ai une solution simple à base de liens symboliques pour regrouper ces répertoires dans un seul système de fichiers:
/var /home -> var/home /root -> var/root /tmp -> var/tmp (ou en tmpfs)
Notez les liens relatifs (il n'y a pas de '/' au début), qui éviteront de mauvaises surprises si je me retrouve à monter les partitions en dehors de leur contexte normal.....
Selon le service fourni par les VMs, je voudrai éventuellement un /srv dédié, dans lequel j'irai stocker sites webs, base LDAP, base SQL, etc....
Idéalement, tout le reste devrait être en lecture seule, dont en particulier:
/ /bin /sbin /etc /usr /lib /boot
En plus, tout ce reste en question représente assez bien le système (l'ensemble des programmes et de la configuration) pour une bonne partie de mes serveurs (hyperviseur inclus), et je serai bien content de pouvoir en faire un snap unique avant une grosse mise à jour des paquets.
Je me retrouve donc avec 3 voire 4 partitions par système (en comptant la partition SWAP), avec un découpage logique tout à fait cohérent pour faire des snaps: root, var, swap et srv.
Il reste juste un petit détail à régler...........
Debian en Read-only Root
Bah oui, un système avec /usr en lecture seule, c'est un peu trop facile, mais avec carrément / en lecture seule, on a un peu plus de trucs à gérer......
Premier point, /root, /var, /home et /tmp. On a déjà réglé ce problème par un /var dédié en lecture/écriture qui contient tout le reste et des liens symbolique depuis la racine.
Le second gros problème, c'est une partie du contenu de /etc. Et il y a déjà une page debian qui regroupe les questions relatives à un système avec / en lecture seule !
A partir de cette liste, que je pense être basée sur des versions plus anciennes de Debian, on peut déjà faire un peu de tri: la plupart des fichiers de configuration problématiques ne seront pas utilisés sur mes serveurs, d'autres sont déjà des liens tels qu'indiqués sur cette page, et une autre partie ne sont pas présents sur mes installations. Voyons ce qu'il reste:
courier imap
Sur la plupart de mes serveurs, il n'y aura pas d'IMAP. Sur le serveur de mail, la configuration sera normalement gérée via LDAP, donc pas besoin d'aller triturer dans /etc.
lvm
Les guests n'utiliseront pas eux même LVM, comme nous allons le voir un peu après. Pour le Dom0, il faudra remonter temporairement / en lecture/écriture pour certaines opérations LVM.
nologin
A tester !
resolv.conf
Mes serveurs auront une configuration DNS statique, donc un resolv.conf qui ne bougera pas, tout va bien.
passwd/shadow
Une fois les systèmes installés, soit les authentifications se feront via LDAP, soit les serveurs auront une configuration très très minimaliste de ce coté là (un compte d'administrateur qui se connecte en SSH par certificats puis qui passe en root), donc les rares changements de mots de passes nécessiteront de remonter temporairement / en lecture/écriture.
udev
Les fichiers indiqués sur la page Debian ne sont plus générés sur Stretch, donc pas de problèmes.
Test
Premier essai sur une VM sur l'ancien hyperviseur (quand je vous dit que tout est fait dans des conditions de sécurité optimales !). Après l'installation (partitions /, /var et swap), on déplace les répertoires nécessaires:
cd / mv root /var/ && ln -s var/root mv home /var/ && ln -s var/home rm -rf /tmp && ln -s var/tmp # /var/tmp existe déjà et doit avoir les mêmes permissions que /tmp
Notez l'absence de "/" pour le ln, comme je l'avais indiqué plus haut. Notez aussi que le "/" final après var pour les mv ne sert pas vraiment, c'est pour bien illustrer le fait qu'on déplace bien les répertoires à l'intérieur de /var.
Ensuite, on édite /etc/fstab:
UUID=[uuid de votre partition ROOT] / ext4 errors=remount-ro 0 1
devient:
UUID=[uuid de votre partition ROOT] / ext4 defaults,ro,noatime 0 1
(je ne suis pas certain que le "noatime" soit vraiment nécessaire)
Reboot, et ......... ça fonctionne ! Limite un peu trop facile, en fait........
Bien sur, pour se simplifier un peu la vie, l'édition de fstab aura lieu quand le système est complètement installé et configuré.
apt full-upgrade
Pour ne pas avoir à faire les manips à la main à chaque installation / mise à jour par apt, on va aller configurer un remontage à la volée, en créant /etc/apt/apt.conf.d/00RWRoot:
DPkg {
// Auto re-mounting of a readonly /
Pre-Invoke { "mount -o remount,rw /"; };
Post-Invoke { "test ${NOAPTREMOUNT:-no} = yes || mount -o remount,ro / || true"; };
};
un joli prompt
Pour savoir d'un coup d'oeil si on a un / en lecture ou en écriture, il suffit de se créer un prompt sympa dans son .bash_profile:
function prompter(){
if [ -z "$(findmnt / |egrep 'ext4\s+rw')" ];then
# Read only
PS1='\[\033[01;36m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
else
PS1='\[\033[01;31m\]\u@\[\033[01;36m\]\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
fi
}
export PROMPT_COMMAND=prompter
J'ai mis un peu de temps à trouver un test fiable pour déterminer si / est en lecture ou lecture/écriture (les tests simples à base de "grep ro" ne fonctionnent pas dans tous les cas). Je ne peux pas garantir que ce test là fonctionne en permanence, on pourrait l'améliorer en vérifiant qu'on a bien soit "ro" soit "rw" (et gérer un 3eme état "sais pas").
Ah, et la notion de joli est subjective, l'important, c'est le principe de prompt dynamique et la technique pour détecter un / en ro ou rw.......
Partition en lecture seule
Pour le Dom0, on en restera là, mais pour les VMs, j'aurais aimé pouvoir vraiment bloquer les accès en écriture au niveau de l'hyperviseur, et les débloquer juste quand j'en ai besoin. Une solution simple consiste à déclarer la partition en lecture seule dans la configuration Xen de la VM, sauf que du coup, "débloquer les accès en écriture" implique de rebooter la VM (je n'ai pas trouvé de commande xl pour faire le changement à la volée).
J'ai également trouvé une option "-p r" / "-p rw" de lvchange, qui permet de changer les permissions du lv. Après quelques essais rapides, je constate bien le changement dans lvdisplay, mais ma VM peut toujours écrire sur le lv (et le changement est bien enregistré). Soit il y a un bug, soit les permissions en question sont autre chose (j'ai trouvé très très peu de documentation sur ce point).
Au passage, si j'en étais resté avec des fichiers pour mes disques de VMs, j'aurais peut être pu facilement faire un chmod........
Master et Snap
LVM permet une autre possibilité intéressante: avoir une partition de référence (le master), et faire fonctionner la VM sur un snap (un dérivé, dans ce cas). Aucun changement sur le snap n'est durable: il suffit de re-générer le snap à partir du master. Redoutable pour nettoyer un serveur compromis, temps de maintenance record (tout peut être préparé en amont, d'un point de vue de la machine de production, c'est juste un reboot), mais assez complexe à gérer au quotidien. Les mises à jour doivent être faites sur le master (soit en démarrant une autre copie de la VM, soit directement depuis le Dom0 à coup de chroot, par exemple), et j'ai déjà vu passer des mises à jour qui font des manipulations sur les données (base de données, etc.....), ce qui complique le suivi.
Bref, l'idée est jolie, je ferai probablement un test un jour sur un serveur secondaire (ou un serveur critique et super statique), mais pour l'instant, je laisse l'idée de coté.
Installation de l'hyperviseur
Le plan de bataille est prêt, il ne reste plus qu'à l'appliquer, à commencer par le Dom0.
Raid miroir, LVM, ROOT et GPT sont dans un bateau.....
Comme je l'avais évoqué au dessus, le BIOS de mon serveur est un peu ancien. Il ne sait donc pas du tout ce que veut dire EFI ou GPT, et c'est déjà bien qu'il détecte mes disques ..... sauf qu'il est à peu près convaincu qu'ils font environ 1.4To chacun.......
Comme le noyau Linux va rapidement lui même tout re-détecter sans se préoccuper du BIOS, y compris les disques (avec leur bonne capacité !), j'ai donc juste besoin que le BIOS réussisse à faire démarrer le noyau. Ma première idée a donc été de réviser légèrement mon plan de partitionnement, avec un petit /boot en début de disque.
Après avoir perdu pas mal de temps à essayer de faire installer GRUB2, j'ai finalement réalisé que l'installeur Debian m'avait créé des tables de partition GPT sur mes disques (alors qu'il m'avait juste demandé si je voulais des tables de partitions, oui/non). Pour que GRUB puisse s'installer sur des disques avec de telles tables, vous devez commencer par créer, au début de chaque disque concerné (les 2 dans mon cas, donc), une petite partition (la littérature sur le net parle de 1Mo comme étant déjà confortable, j'en ai mis 2 pour être installé en VIP.....) de type "BIOS Boot Partition" (disponible dans la liste des types de partitions durant l'installation). Cette partition n'est pas en RAID miroir: GRUB n'ira pratiquement jamais la modifier (il y a juste une partie du code de GRUB, pas de configuration), et si jamais il le fait, nous allons de toutes façons lui indiquer par la suite qu'il doit s'installer sur les 2 disques.
Avec cette petite diversion, j'en ai un peu oublié de créer mon /boot dédié, et je m'en suis rendu compte assez tard dans l'avancement du nouveau serveur.....
En pratique, mon installation démarre. D'après lvdisplay -m, ma partition dom0root est physiquement au début du disque et devrait y rester, en tout cas tant que je ne l'étends pas, donc l'image du noyau et de l'initrd devraient rester accessibles (tant que je n'étends pas dom0root, donc.......). Comme j'ai quand même pris un peu de marge sur la taille de cette partition et que je prévois vraiment de ne pas avoir grand chose du tout d'installé directement sur l'hyperviseur, je prends le risque de rester avec ce découpage. Si ça se trouve, GRUB est peut être assez intelligent pour savoir adresser l'ensemble des disques durs, même s'ils ont mal été détectés par le BIOS..... Si vous vous retrouvez vous aussi à jouer avec des disques partiellement reconnus par votre BIOS...... faites un /boot dédié !
Ce petit problème étant résolu, voici le résumé de ce qu'il faut faire pour préparer ses disques dans l'installeur Debian:
- Création d'une table des partitions sur les 2 disques s'ils sont neufs. Créer si nécessaire la partition "BIOS Boot Partition", donc.....
- En cas de nécessité, créer un tout petit RAID en tout début de disque pour /boot, donc......
- Créer une partition qui occupe tout le reste de l'espace sur chaque disque (elles s'appelleront probablement /dev/sdaX et /dev/sdbX, avec X=3 si vous avez créé la partition BIOS Boot Partition et la partition raid /boot, X=2 si vous n'avez créé que l'une des deux partitions citées à l'instant, et X=1 si vous n'en avez créé aucune des deux), et indiquer comme utilisation "physical volume for RAID".
- Configure software RAID: RAID1, 2 devices actives, 0 spare, sélection des 2 partitions créées au dessus (probablement /dev/sdaX et /dev/sdbX, donc).
- Configurer cette partition RAID (probablement /dev/md0, ou /dev/md1 si vous avez créé un /boot aussi en RAID1) comme "use as physical volume for LVM"
- Configure LVM:
- Create volume group (que nous appellerons vg0 dans le reste du billet, mais vous pouvez nommer le votre toto89324xfza si ça vous fait plaisir......), sélection de la partition md créée juste au dessus.
- Create logical volume sur vg0 pour root, var et swap. Pour plus de lisibilité, j'ai nommé les miens dom0root, dom0var et dom0_swap, mais là aussi, vous pouvez mettre les noms arbitraires de votre choix....
- Retour au menu de partitions, affectation des lv sur /, /var et swap
- Pendant la conf de grub, choisir l'installation sur le secteur de démarrage, et indiquer le premier disque (sda)
- après le reboot, dpkg-reconfigure grub-pc (ou dpkg-reconfigure grub-efi-amd64 si vous bootez en EFI, d'après ce que j'ai lu sur certaines docs) et sélection de sda et sdb (pour des mises à jour futures de grub). Là, je suppose qu'il s'installe sur sdb sans commande supplémentaire, mais comme je l'avais fait durant l'installation, je n'ai pas pu vérifier !
Et c'est parti pour ...... environ 10h de synchro du miroir dans mon cas !
Avec lvm, on peut faire plus subtil: créer un premier md relativement petit (20Go suffisent très très largement pour une install minimaliste d'une Debian serveur), qui va se synchroniser très rapidement durant l'installation (alors que la synchro du mien a plombé très sévèrement la vitesse d'installation de base du système !), et plus tard, à un moment tranquille, on crée un ou plusieurs autres gros md qu'on ajoute à vg0..... En utilisant cette technique, on pourrait aussi forcer dom0_root à être dans md0, qui est au début du disque, ce qui serait une autre façon de s'assurer que l'image du noyau restera dans la partie du disque accessible via le BIOS.
Configuration du Dom0
Quitte à détailler l'installation, petit rappel express pour transformer une "install Debian" en "install Debian Dom0":
apt install xen-system-amd64 dpkg-divert --divert /etc/grub.d/08linuxxen --rename /etc/grub.d/20linuxxen
Edition de /etc/default/grub (dans l'exemple, je lui réserve 2Go de RAM, vous ajusterez selon votre cas, j'ai le vague souvenir qu'il ne faut pas lui mettre trop peu):
GRUBCMDLINEXEN="dom0_mem=2048M,max:2048M"
/etc/xen/xend-config.sxp
(dom0-min-mem 2048) (enable-dom0-ballooning no)
Ces 2 changements disent en gros que le Dom0 aura 2Go de mémoire dédiée pour lui, mais qu'il ne touche pas au reste, c'est pour les potes....
On applique les changements de la configuration de grub:
update-grub
Un petit reboot et on est bon !
Création des disques d'une VM
lvcreate -n guest1_root -L 2G vg0 /dev/md0 lvcreate -n guest1_var -L 2G vg0 /dev/md0 lvcreate -n guest1_swap -L 1G vg0 /dev/md0
A la fin de la ligne, /dev/md1 sert à s'assurer que ces LVs seront bien sur md0 (chez moi, c'est md0, chez vous, ca sera donc peut être md1, voire autre chose), même si plus tard on rajoute d'autres disques, partitions RAID ou je ne sais quoi d'autre.
L'option -n permet d'indiquer le nom du lv.
L'option -L permet de spécifier la taille, ici 2Go pour les partitions root et var (ce qui sera largement suffisant pour la plupart de mes installs serveurs, et il sera toujours temps d'agrandir les lv plus tard si besoin), et 1Go pour le swap.
Et vg0 pour indiquer le vg sur lequel on souhaite créer tout ça (oui, on pourrait avoir plusieurs vgs, et même que ça pourrait être pertinent dans certains cas).
Le fichier de conf Xen de la VM va donc contenir (j'ai viré ce qui ne concerne pas directement les disques):
boot = "pygrub"
# Uniquement pour le boot d'install depuis l'ISO
bootloader_args = [
"--kernel=/install.amd/xen/vmlinuz",
"--ramdisk=/install.amd/xen/initrd.gz"
]
disk = [
# uniquement pour l'install
'file:/home/Xen/debian-9.3.0-amd64-netinst.iso,hdc:cdrom,r',
'phy:/dev/vg0/guest1_root,xvda1,rw',
'phy:/dev/vg0/guest1_var,xvda2,rw',
'phy:/dev/vg0/guest1_swap,xvda3,rw',
]
Et ca ne fonctionne pas: l'installer Debian voit bien qu'il s'agit de partitions, mais ne comprend pas leur type, et veut désespérément leur générer un MBR comme s'il s'agissait de disques....
Il faut donc d'abord créer les filesystem depuis le dom0:
mkfs.ext4 /dev/vg0/guest1_root mkfs.ext4 /dev/vg0/guest1_var mkswap /dev/vg0/guest1_swap
puis recommencer l'installation (ou me croire sur parole, et exécuter ces commandes avant la première installation.......).
Avec cette configuration, grub ne s'installe pas. A vrai dire, ce n'est pas très grave, vu qu'il n'est pas directement utilisé (c'est pygrub qui fait le boulot depuis le Dom0). J'ai trouvé chez Debian une solution, qui consiste à créer le fichier /boot/grub/menu.lst suivant dans la VM:
default 0 timeout 0 title Debian GNU/Linux root (hd0,0) kernel /vmlinuz root=/dev/xvda1 ro initrd /initrd.img
Soit vous montez la partition depuis le Dom0 après l'installation, soit, à la fin de l'installation, vous le créez dans un shell:
mkdir /target/boot/grub cat >/target/boot/grub/menu.lst
(et vous faites un copier/coller du fichier juste au dessus).
Comme le but est de filer les infos à pygrub, on peut aussi s'en sortir avec les paramètres root et bootloader_args du fichier de configuration de la VM:
bootloader_args = [ "--kernel=/vmlinuz", "--ramdisk=/initrd.img" ] root = '/dev/xvda1 ro'
Une VM en img vers LVM
Pour ma VM de firewall, la méthode décrite au dessus ne fonctionne pas: je dispose d'une image de VM au format OVA toute prête, et je ne peux pas faire ce que je veux au niveau des partitions, donc je vais utiliser un lv pour stocker directement cette image:
root@dom0:~ $ tar xf firewall.ova root@dom0:~ $ ls *.vmdk firewall.vmdk root@dom0:~ $ qemu-img convert -O raw firewall.vmdk firewall.img root@dom0:~ $ qemu-img info firewall.img image: firewall.img file format: raw virtual size: 10G (10738466816 bytes) disk size: 843M
Nous disposons maintenant d'une image RAW de la VM (bien sur, selon votre format d'origine, vous adapterez les premières étapes), et de sa taille exacte à l'octet près. Il ne reste plus qu'à créer un lv de cette taille (notez bien le b
à la fin de la taille, par défaut lvcreate considère une autre unité) et à copier l'image:
root@dom0:~ $ lvcreate -n firewall_root -L10738466816b /dev/vg0 root@dom0:~ $ dd if=firewall.img of=/dev/vg0/firewall_root bs=1M
Et voilà !
Opérations de maintenance
Remplacement de disque physique
Ca fait pas mal de temps que je n'ai pas eu besoin de remplacer un disque (mais j'ai déjà eu plusieurs fois à le faire depuis que je stocke mes données en RAID1.....), du coup, pour l'instant, je consigne ici ce que j'ai trouvé comme infos sur le net.
Dites "33"
Première chose à faire, repérer le disque qui pose problème:
root@dom0:~$ cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb2[0]
7813892096 blocks super 1.2 [2/1] [U_]
bitmap: 0/59 pages [0KB], 65536KB chunk
Dans ce cas, c'est sda qui serait défaillant, nous partirons de ce principe pour tout le reste de l'exemple.
Attention chérie, ca va couper....
Maintenant qu'on connaît le disque fautif, nous allons confirmer à mdadm qu'il doit le considérer comme tel:
root@dom0:~$ mdadm --manage /dev/md0 --fail /dev/sda2
Dans mon cas, je n'ai que md0, et il est constitué de sda2 et sdb2. Si vous avez plusieurs md qui utilisent le disque défectueux, l'opération est à recommencer pour chaque partition. Les opérations suivantes aussi.....
Il est maintenant possible de l'enlever du RAID:
root@dom0:~$ mdadm --manage /dev/md0 --remove /dev/sda2
Une fois le disque complètement sorti du RAID, vous pouvez éteindre le serveur, remplacer le disque par un nouveau, et redémarrer (si votre configuration est bonne, vous saurez booter sur le disque encore actif du RAID, ce qui nécessitera peut être quelques manips au niveau du BIOS/EFI dans le cas où c'est justement sda qui a laché).
Le nouveau disque
Commencez par vérifier que vos disques ont toujours les mêmes noms ! Il semblerait que, dans certains cas, votre ancien sdb puisse être votre nouveau sda, et ca serait vraiment vraiment une mauvaise idée d'appliquer les manipulations ci après à l'envers !! Supposons cependant que l'ancien sdb soit toujours sdb, et que le disque tout neuf ait pris le nom de celui qu'il remplace: sda.
Première étape, il faut partitionner le nouveau disque. Plusieurs options sont possibles, y compris une construction manuelle de la table des partitions, mais si votre nouveau disque fait exactement la même taille que l'ancien, le plus rapide est de faire:
root@dom0:~$ sfdisk -d /dev/sdb | sfdisk /dev/sda
Nous pouvons maintenant ajouter la nouvelle partition au RAID1:
root@dom0:~$ mdadm --manage /dev/md0 --add /dev/sda2
A partir d ce moment, vous pouvez aller vérifier que le md a commencé à se synchroniser en faisant un cat /proc/mdstat. Et vous pouvez du coup aussi vous installer pour quelques heures d'angoisse, en attendant que la synchro soit finie (donc que toutes vos données soient à nouveau à l'abri sur 2 disques......).
Grub
Et il faudra aussi installer Grub sur le nouveau disque. A priori, ca devrait se faire via la commande suivante:
root@dom0:~$ grub-install /dev/sda
J'espère qu'il se passera plusieurs années avant que je ne puisse venir éditer ce billet et confirmer que cette séquence fonctionne.........
Extension de la taille d'une partition de VM
Déjà, on va vérifier qu'il reste de la place dans le vg:
root@dom0:~$ vgdisplay /dev/vg0
[.......]
Free PE / Size xxxxx / Place libre
Ok, disons qu'il reste de la place, ajoutons donc 2Go sur la partition root de guest1:
root@dom0:~$ xl shutdown guest1 Shutting down domain X Waiting for 1 domains Domain X has been shut down, reason code 0 root@dom0:~$ lvresize -r -L +2G /dev/vg0/guest1_root [.......] root@dom0:~$ xl create /etc/xen/guest/guest1.xl
Et ...... c'est ....... tout !!!!! (c'est le -r qui dit à lvresize de faire faire dans la foulée le boulot de redimensionnement du filesystem en dessous). Enfin, presque: si vous avez le / de votre dom0 en lecture seule, il faut le repasser en lecture/écriture pour le lvresize, ce qui donne au final les commandes suivantes:
root@dom0:~$ xl shutdown -w guest1 && mount -o remount -w / && lvresize -r -L +2G /dev/vg0/guest1_root && mount -o remount -r / && xl create /etc/xen/guest/guest1.xl
Avec une bonne politique de nommage des volumes logiques, ca doit même pouvoir se scripter très facilement, en fait....... d'un autre coté, si le script est rentable, c'est que vous passez votre temps à redimensionner vos partitions, et vous pouvez vous poser d'autres questions, dans ce cas !
Snapshot d'une VM
Un snapshot LVM ne fait pas une véritable copie complète du lv d'origine: il retient son état au moment du snapshot, puis va uniquement stocker les changements (enfin, les anciennes versions avant changement, pour être précis). Nous allons donc allouer au snapshot une taille nettement inférieure à celle du volume d'origine s'il s'agit juste de faire une sauvegarde avant un changement de configuration un peu risqué. Par contre, s'il s'agit d'une sauvegarde juste avant une très très grosse mise à jour de version, par exemple, il faudra prévoir une taille assez conséquente pour le snapshot !
Créons donc un snapshot d'1Go de la partition root de guest1 (la VM est éteinte depuis quelques secondes, je ne sais pas trop s'il est possible/fiable de faire un snap d'une VM en cours de fonctionnement):
root@dom0:~$ lvcreate -L1G -s -n guest1_root_snap1 /dev/vg0/guest1_root
Et voilà..... l'opération ne prend que quelques secondes, on peut redémarrer guest1 de suite.
Si vous voulez faire une bonne vieille sauvegarde à l'ancienne de votre partition, dans un bon vieux fichier que vous pouvez stocker ailleurs, vous pouvez le faire sur le snap pendant que la VM a été redémarrée:
root@dom0:~$ dd if=/dev/vg0/guest1_root_snap1 bs=1M | bzip2 -9 > guest1_root_save.raw.bz2
Ce fichier sera restaurable sur le lv d'origine (VM stoppée) avec la commande suivante:
root@dom0:~$ bunzip2 -c guest1_root_save.raw.bz2 | dd of=/dev/vg0/guest1_root bs=1M
Dans les 2 cas, vous pouvez jouer avec l'option bs de dd (block size), d'autres valeurs pourraient vous permettre de gagner pas mal de temps sur l'opération (ou d'en perdre pas mal.....).
Quand votre snapshot ne sert plus à rien, il est détruit comme n'importe quel autre lv:
root@dom0:~$ lvremove /dev/vg0/guest1_root_snap1
Si par contre vous avez bien fait de faire un snap et que vous avez besoin de le restaurer, l'opération est un peu plus longue, et se fait via la commande suivante (avec la VM stoppée):
root@dom0:~$ lvconvert --merge /dev/vg0/guest1_root_snap1
N'apparaissent pas au générique de fin.......
Inévitablement, j'ai fait des choix à certains moments. Quelques uns méritent un peu plus d'explications.
LVM dans du LVM
Au début, on m'avait proposé l'idée de faire une partition LVM au niveau de l'hyperviseur pour chaque guest, et de considérer au niveau du guest cet ensemble comme un disque, donc de faire des partitions dessus, et tant qu'à faire en LVM aussi. Le fait d'empiler 2 niveaux de LVM semblait ne pas poser de gros problèmes de performances, mais c'est quand j'ai regardé comment étendre les partitions des VMs que j'ai décidé de renoncer à cette solution. En gros, il fallait étendre le lv coté hyperviseur (jusque là, ca me parait prévisible......), démarrer la VM, créer une partition sur l'espace supplémentaire désormais disponible, rajouter cette partition au vg du guest, et seulement après on pouvait à nouveau faire un lvextend au niveau du guest...... Pour les éventuelles réductions de taille de partition, même si ca ne devrait pas m'arriver en pratique, je n'ai même pas osé trop réfléchir à la séquence de trucs à faire !
Sur ce point, il semble cependant y avoir une alternative qui réduit un peu les manipulations: au niveau de la VM, ne pas faire de partition, mais embarquer l'ensemble du disque comme un PV, ce qui permettrait semble-t-il de redimensionner directement le vg dessus avec un pvresize après avoir étendu le lv au niveau du Dom0 (si vous avez compris cette phrase du premier coup, ne prenez pas le volant !). Notez que je n'ai pas testé, et qu'il s'agit donc d'une solution théorique à ma connaissance.
Dans tous les cas, ca m'aurait aussi un peu compliqué la vie au moment de faire des snaps: soit j'aurais du faire des snaps complets des VMs (root + var + swap + srv) au niveau de l'hyperviseur, soit ...... euh ..... j'aurais du réfléchir à comment balancer de l'espace en plus à la VM pour qu'elle fasse elle même son snap.
xen-tools
Plusieurs tutoriels font de la création de VMs avec xen-tools. Vu que je ne prévois pas de faire régulièrement de création de nouvelles VMs, je n'ai pas trop cherché à utiliser cette solution.
debootstrap
Il est également possible de créer une VM Debian sans la démarrer via debootstrap. Un peu comme pour les xen-tools, j'ai été plus vite à court terme en créant mes VMs en mode "classique", mais je m'intéresserai clairement à cette possibilité si je me rends compte que j'ai à fabriquer plus ou moins régulièrement de nouvelles VMs à l'avenir.
Thin provisioning
LVM supporte (depuis peu ?) le principe de thin provisioning. En gros, c'est la même idée que le surbooking, mais pour l'espace disque..... Je suppose que c'est assez pratique dans certains cas, mais dans le mien, je n'aime pas trop l'idée de vivre à crédit sur mon espace disque, surtout que je n'en ai pas besoin.
RAID1 via LVM
LVM gère depuis pas mal de temps une option "mirror". Pour le peu que j'en ai lu sur le net, l'objectif de ces mirrors est différent, et nettement moins pertinent que mdadm pour gérer un RAID1 de disques.
Depuis beaucoup moins de temps, LVM gère également un mode RAID1 (entre autres), qui semble lui très très proche d'un point de vue fonctionnel du RAID1 avec mdadm. J'ai repéré cette possibilité alors que j'avais déjà pas mal avancé sur mon installation, et le coté un peu nouveau de la solution a aussi contribué à ce que je laisse cette idée de coté.
Pour une version ultérieure, la question se posera peut être, mais j'avoue que pour l'instant, j'aime bien l'idée d'avoir rapidement une vue purement RAID d'un coté, et une gestion d'un seul "truc" (le md0) de l'autre.
FreeNAS
Pour le NAS, à un moment, je me suis posé la question d'utiliser FreeNAS, son fork Nas4Free ou une autre distrib dédiée. Au début, je n'avais pas mes 48Go de RAM, donc j'avais laissé tomber.
En plus, dans mon cas d'usage, les avantages de ZFS ne sont pas flagrants, mon install de VM NFS finale est vraiment réduite au strict nécessaire, et je n'ai pas creusé l'empilage LVM/ZFS.
Des trucs annexes....
Là, on sort des problématiques d'organisation de disques, mais si ces infos peuvent servir à des gens plus tard (dont potentiellement moi), alors tant mieux !
Ordre d'arrêt des VMs
Par défaut, lors de l'arrêt de l'hyperviseur, le script /etc/init.d/xendomains est appelé, et stoppe les VMs dans l'ordre inverse de leur création. Tant que vos VMs ne rebootent pas, l'idée peut sembler pertinente......
Une solution absolument propre consisterait à connaître un graphe de dépendance des VMs, et à stopper par lots en fonction de ces dépendances. Par exemple:
- je stoppe le firewall HA passif en tache de fond
- je stoppe tous les clients (qui dépendent du firewall, du NFS, du DNS, etc....)
- puis je stoppe les serveurs publics
- puis je stoppe les serveurs privés
- puis je stoppe le firewall
- puis je reboote.
Bien évidemment, dans ce monde parfait, les dépendances sont listées dans les fichiers de configuration.....
A défaut de ce monde parfait, voyons quelles solutions nous pouvons mettre en place.
Intercepter l'ordre de la liste
L'idée est de disposer de notre propre script, que j'ai dans mon cas placé en tant que /usr/lib/xen-common/bin/xen-list-domains (pensez à lui donner les droits d'exécution, bien sur !).
Nous allons alors détourner l'appel dans xendomains pour qu'il obtienne sa liste (et donc l'ordre) de notre script:
--- /etc/init.d/xendomains.old
+++ /etc/init.d/xendomains
-185,12 +185,12 dostopshutdown()
logactionbegin_msg "Shutting down Xen domain $name ($id)"
xen shutdown $id 2>&1 1>/dev/null
logactionend_msg $?
- done < <(/usr/lib/xen-common/bin/xen-init-list)
+ done < <(/usr/lib/xen-common/bin/xen-list-domains)
while read id name rest; do
logactionbegin_msg "Waiting for Xen domain $name ($id) to shut down"
timeoutdomain "$name" "$XENDOMAINSSTOP_MAXWAIT"
logactionend_msg $?
- done < <(/usr/lib/xen-common/bin/xen-init-list)
+ done < <(/usr/lib/xen-common/bin/xen-list-domains)
}
do_stop()
Nous avons toujours un arrêt en masse des VMs, mais au moins dans l'ordre qui nous arrange..... un xen shutdown -w serait potentiellement dangereux, vu qu'il n'existe apparemment pas d'option pour dire "attends x secondes maximum".
Il ne nous reste plus qu'à voir ce qui est faisable avec xen-list-domains
Nommage des VMs
Ma première tentative a été de mettre l'ordre en tant que nom des VMs: 01-firewall, 55-client, 99-firewall-slave, etc....
Du coup, xen-list-domains est assez simple:
#!/bin/bash
while read name id mem cpu state time ; do
if [ "$name" != "Name" -a "$name" != "Domain-0" ];then
echo "$id $name"
fi
done < <(xl list|sort -r)
Cette approche présente 2 inconvénients:
- Ca devient vite lourd de devoir se souvenir des numéros de priorité des VMs, qui sont du coup leurs noms aussi.....
- Le script ne fonctionne pas au reboot.... Apparemment,
xen-init-listse comporte un peu différemment pendant le reboot.
Script autonome
Du coup, j'ai fait une 2eme tentative en appelant xen-init-list, mais je ne peux plus trier directement via sort (on doit pouvoir le faire via awk ou un truc du genre, mais je ne suis pas expert). Donc je me suis retrouvé à faire mon nouveau xen-list-domains en perl (là, je sais faire). Et quitte à le faire en perl, je peux embarquer les priorités dans le script:
#!/usr/bin/perl
my %vmorder = (
"firewall" => 99,
"firewall-slave" => 0,
"guest1" => 2,
"srvnfs" => 98,
"guest2" => 3,
"srvlan" => 97,
"srvpub" => 80,
"machin" => 40,
);
my %vmreal;
open(LIST, "/usr/lib/xen-common/bin/xen-init-list|");
while($line=<LIST>){
my $order;
my ($id, $name, @rest) = split(/ /, $line);
chomp $name;
if(defined($vmorder{$name})){
$vmreal{$line}=$vmorder{$name};
}else{
$vmreal{$line}=1;
}
}
close(LIST);
foreach (sort { $vmreal{$a} <=> $vmreal{$b} } keys %vmreal) {
print ;
}
Les VMs non connues ont un poids de 1. Une VM qui a un poids de 0 explicite recevra son signal d'arrêt en premier, puis les VMs non connues, puis les autres connues dans l'ordre de poids (donc dans mon cas, 99 sera la dernière à recevoir son signal).
Dans une version ultérieure, je pourrais stocker les priorités ailleurs (dans les fichers de conf des VMs ?), voire les calculer à partir de dépendances. Vu que mes VMs et leurs dépendances sont assez statiques, je n'ai pas passé plus de temps sur cette partie.
En pratique, quand j'ai besoin de redémarrer l'hyperviseur, je préfère stopper manuellement toutes les VMs, et il est important de faire ca dans un screen, tmux, ou toute autre solution qui permettra que les dernières commandes soient effectivement lancées même quand votre terminal se fera couper le ssh sous le cable !